 data_excel
data_excel
See also: data_csv, data_database
Excel files (together with CSV files and databases) are probably the most important data source for Stagraph. Excel is the most important because is widespread among users. Excel is very easy to use tool for data handling. Due to this fact, Excel is frequently used for data archiving, sharing and processing. Therefore, this data source belongs to an important place within the Stagraph. The following video-tutorial shows you how to import data from excel files.
For data import from Excel files is the readxl package used. For the import itself, the read_excel function is applied. If you want to import Excel files into Stagraph, you do not have MS Office installed on your computer. The readxl package has no external dependencies.
Function properties
| path / file |
Path to the xls / xlsx file |
| sheet |
Sheet to read. Either a string (the name of a sheet), or an integer (the position of the sheet). Ignored if the sheet is specified via range. If neither argument specifies the sheet, defaults to the first sheet. |
| range |
A cell range to read from, as described in cell-specification. Includes typical Excel ranges like "B3:D87", possibly including the sheet name like "Budget!B2:G14", and more. Interpreted strictly, even if the range forces the inclusion of leading or trailing empty rows or columns. Takes precedence over skip, n_max and sheet. |
| col_names / header |
TRUE to use the first row as column names, FALSE to get default names, or a character vector giving a name for each column. If user provides col_types as a vector, col_names can have one entry per column, i.e. have the same length as col_types, or one entry per unskipped column. |
| col_types |
Either NULL to guess all from the spreadsheet or a character vector containing one entry per column from these options: "skip", "guess", "logical", "numeric", "date", "text" or "list". If exactly one col_type is specified, it will be recycled. The content of a cell in a skipped column is never read and that column will not appear in the data frame output. A list cell loads a column as a list of length 1 vectors, which are typed using the type guessing logic from col_types = NULL, but on a cell-by-cell basis. |
| NA strings |
Character vector of strings to use for missing values. By default, readxl package treats blank cells as missing data. |
| trim ws |
Should leading and trailing whitespace be trimmed? |
| skip |
Minimum number of rows to skip before reading anything, be it column names or data. Leading empty rows are automatically skipped, so this is a lower bound. Ignored if range is given. |
| n_max |
Maximum number of data rows to read. Trailing empty rows are automatically skipped, so this is an upper bound on the number of rows in the returned tibble. Ignored if range is given. |
| guess_max |
Maximum number of data rows to use for guessing column types. |
Description
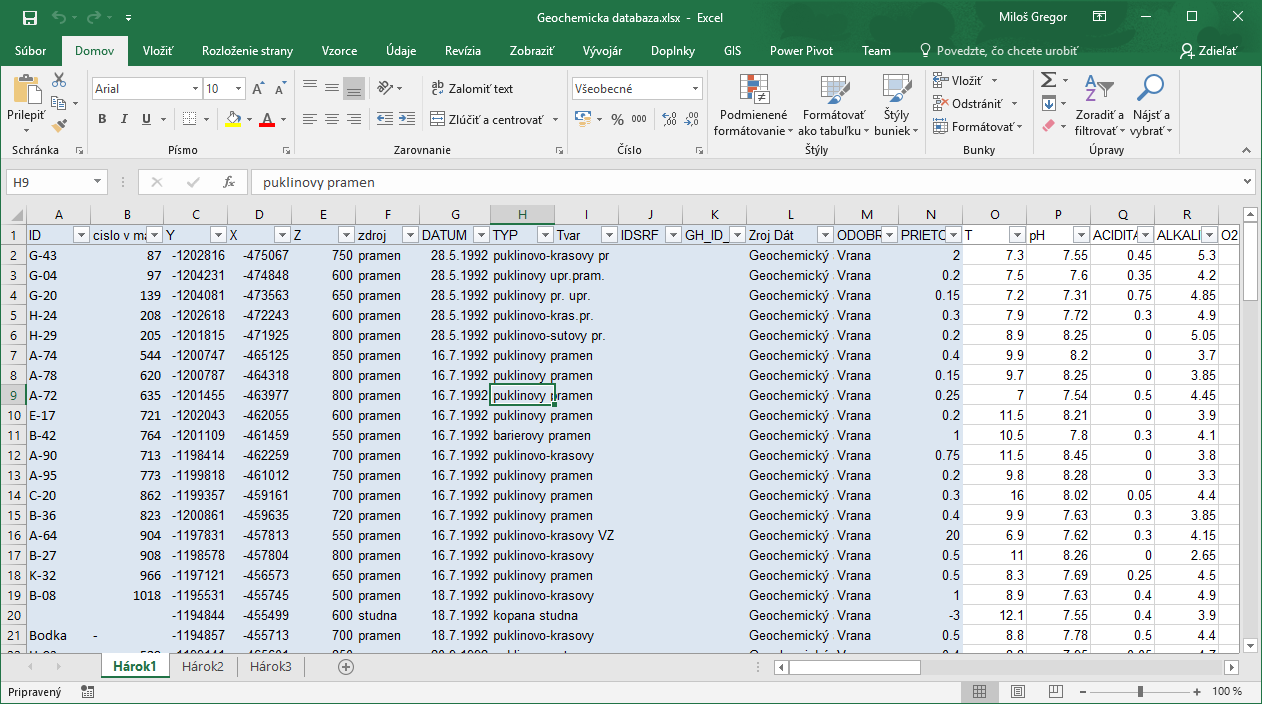
To import data from Excel files, press the File button in the ribbon toolbar and click the Excel File item in menu that appears.
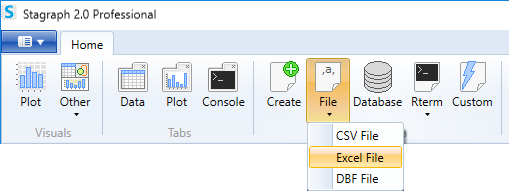
Help dialog appears as in the following picture. Here you can set four properties. At first, define the file you want to import. For this purpose the Open button is used.
The R Environment specifics is that the slash mark (“/") is used as the directories separator, instead of the backslash (“\"). If you paste the file name manually, you must also manually change these separators. If you define it using the Open button, separators are set automatically in the correct form.
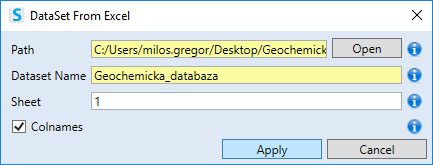
In the following text-box you type the name of the dataset in Stagraph. By default, the file name is used (without the xls or xlsx extension). Then, use the Sheet property to define the sheet from which your data will be loaded. By default, the data is searched in the first sheet in sequence. You can define the Sheet property in two ways. It can be defined by the order number or by its name. If you use a number, write an integer number. If you’re using a sheet name, enclose the name in quotes. Finally, with the col_names check-box you can define whether the variable names are located in the first row. If you have all parameters defined, click the Apply button and the selected file will be imported.
Resulting dataset is after the execution displayed in the datasets list in Project Panel and you can also preview the dataset within the Data Preview Document.
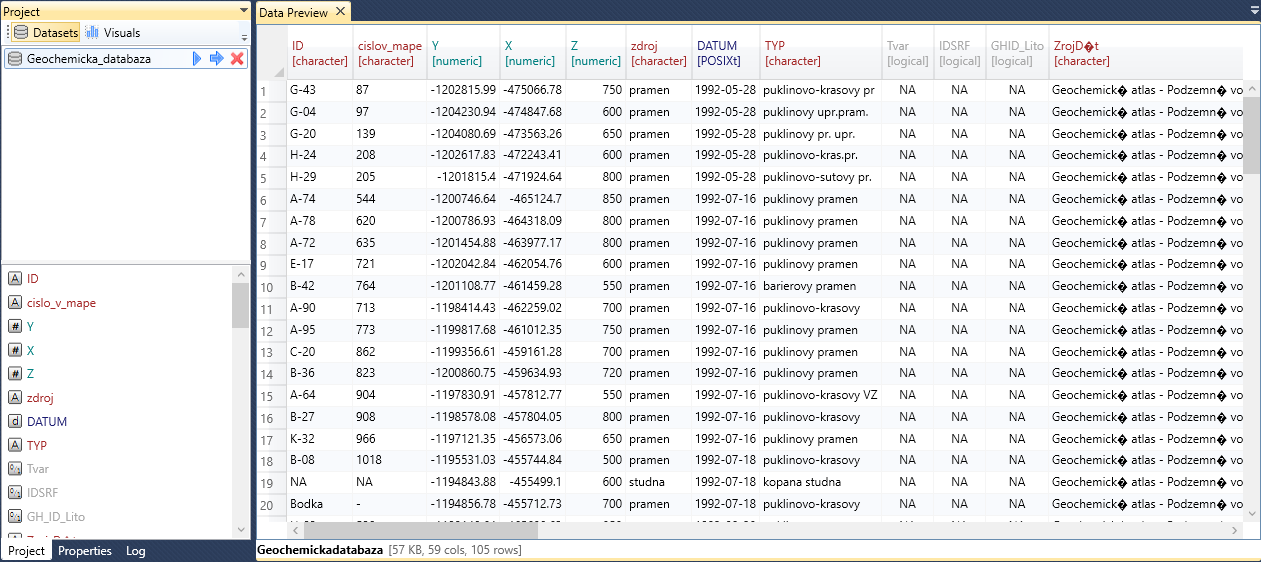
In addition to the described import parameters, it is also possible to define other in the Properties Panel. In this panel, you can set additional properties such as cell range, skip or col types. These settings are displayed at the bottom part of panel if you click on the data_excel function.
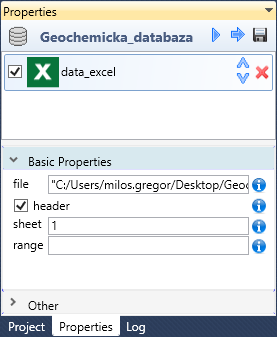
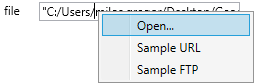
Using the first text-box (named file), you can change the source file from which the data will be retrieved. In the text-box contextual menu you find three items. Using the first one you can show the Open File Dialog to select the file on disk. The other two serves as an examples if you want to download Excel file from a server or you can load it through an FTP protocol. If you click on these items, an examples appears in the text-box. These examples you can adjust precisely according to your needs.
Using the header checkbox, you can set whether variable names are stored in the first row of the imported dataset.
With the sheet property, you can define the Excel sheet from which you can load the data. As in previous cases, you can find use examples in contextual menu - definition of the sheet through its order number and its name.

The described parameters can be defined in the input dialog for Excel files or in the Properties Panel. The following setup options are available only within the Properties Panel. The first adjustable property from this group is the range property.
Using this parameter, you can precisely define the range of sheet cells from which the data will be loaded. If the range is not defined (default option), your data will be read from the entire sheet. Examples of setting options are in text-box contextual menu. If you click on the selected option from the context menu, an example will be added to the text-box and you only modify it to the required form.
As it is clear from the picture, the range property can be defined in several ways. You can use standard Excel notation - “A1:E15" or “Sheet1!A1:E15", you can define range of columns or rows, you can define the starting cell and number or rows / columns.
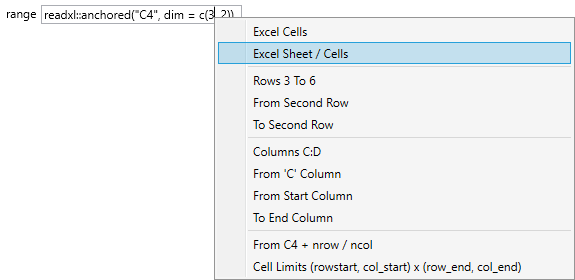
Once this parameter is set, Stagraph will only read the data from selected cell range. Other setting options are located in the second section - Other.
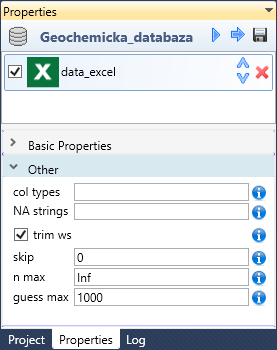
In the second section of function properties you find as the first parameter - col types. With this property you can set the data format that will be applied to variables at import. This format can be defined at once for all columns (the same type, e.g. string or numeric) or for individual columns. You can find the individual setting options in the text-box contextual menu. More about this property you can find here.
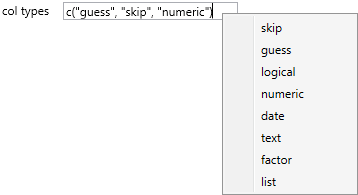
If you set this property as “skip", selected variable (column) will be omitted from the import. If a column will be defined as “guess", its format will be detected automatically from data. Other data types already defining specific types, e.g. logical, numeric, date or text.
Sometimes it can happen that the data in source file are in wrong format. In this case it can be useful to define all columns as “text". With this setting, all values will be read as text strings. Subsequently, you can format them directly in the program using built-in Data Wrangling functions.
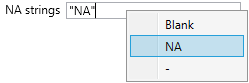
Using the NA strings parameter you can define missing values in the source file. By default the program recognizes only empty cells as missing values. This feature you can adjust. In the contextual menu, you will find definition examples. This property you can set as one or multiple strings. If you use only one value, write it into the text-box and enclose it into the quotes - for example “NA". If you use multiple definitions, write them as an array using the c function, for example:
c(“NA","No Data", “?")
With this setting, the program mark all cells with these values as missing.
Finally, the last four adjustable parameters remains. Using the trim ws checkbox you can define whether the leading and trailing whitespace will be trimmed. With the skip parameter, you can set the number of rows (from the sheet beginning) that will be skipped at import. This property is used only if the range parameter has not been set. Another argument is n max and defines the maximum rows that can be used for import. If the property is to Inf, all rows will be used. Like the skip property, it is used only if you don’t use the the range property. Finally, with the guess max argument, you can set the number of rows to be scanned for data type detection. By default, this property is set to 1,000.

With the data_excel function, you can import data from Excel files into Stagraph. Individual settings allows you to define the data import in detail. Together with features from the Data Wrangling group forms a very powerful tool for automated processing of Excel files.