 data_csv
data_csv
See also:
data_database,
data_excel
A comma-separated values (CSV) file is a delimited text file that uses a comma to separate values. A CSV file stores tabular data (numbers and text) in plain text. Each line of the file is a data record. Each record consists of one or more fields, separated by commas. The use of the comma as a field separator is the source of the name for this file format.
If you are working with data, probably very often you encounter data in CSV format. Import and export of CSV files supports a large number of programs and platforms. Due to their “readability" CSV files are often used to exchange and archive data. Stagraph fully supports this data format. The following video contains an intro tutorial for working with CSV Files in Stagraph.
To import data from CSV files, the read.table function from the utils package is used.
Function Properties
| file, file name |
the name of the file which the data are to be read from. Each row of the table appears as one line of the file. This can be a compressed file. file can also be a complete URL. |
| header, include header |
a logical value indicating whether the file contains the names of the variables as its first line. If missing, the value is determined from the file format: header is set to TRUE if and only if the first row contains one fewer field than the number of columns. |
| sep, columns separator |
the field separator character. Values on each line of the file are separated by this character. If sep = "" (the default for read.table) the separator is white space, that is one or more spaces, tabs, newlines or carriage returns. |
| quote |
the set of quoting characters. To disable quoting altogether, use quote = "". Quoting is only considered for columns read as character, which is all of them unless col classes is specified. |
| dec, decimal separator |
the character used in the file for decimal points. |
| col names |
a vector of optional names for the variables. The default is to use "V" followed by the column number |
| as.is |
the default behavior of read.table is to convert character variables (which are not converted to logical, numeric or complex) to factors. The variable as.is controls the conversion of columns not otherwise specified by colClasses. Its value is either a vector of logicals (values are recycled if necessary), or a vector of numeric or character indices which specify which columns should not be converted to factors. Note: to suppress all conversions including those of numeric columns, set colClasses = "character". Note that as.is is specified per column (not per variable) and so includes the column of row names (if any) and any columns to be skipped. |
| NA strings |
a character vector of strings which are to be interpreted as NA values. Blank fields are also considered to be missing values in logical, integer, numeric and complex fields. Note that the test happens after white space is stripped from the input, so na.strings values may need their own whitespace stripped in advance. |
| col classes |
a vector of classes to be assumed for the columns. If unnamed, recycled as necessary. If named, names are matched with unspecified values being taken to be NA. Possible values are NA (the default, when type.convert is used), "NULL" (when the column is skipped), one of the atomic vector classes (logical, integer, numeric, complex, character, raw), or "factor", "Date" or "POSIXct". Otherwise there needs to be an as method (from package methods) for conversion from "character" to the specified formal class. |
| nrows, read N rows |
integer. The maximum number of rows to read in. Negative and other invalid values are ignored. |
| skip |
integer. The number of lines of the data file to skip before beginning to read data. |
| check names |
logical. If TRUE then the names of the variables in the data frame are checked to ensure that they are syntactically valid variable names. If necessary they are adjusted (by make.names) so that they are, and also to ensure that there are no duplicates. |
| fill |
logical. If TRUE then in case the rows have unequal length, blank fields are implicitly added. |
| strip white |
logical. Used only when sep has been specified, and allows the stripping of leading and trailing whitespace from unquoted character fields (numeric fields are always stripped). See scan for further details (including the exact meaning of white space), remembering that the columns may include the row names. |
| blank lines skip |
logical. If TRUE blank lines in the input are ignored. |
| comment char |
character. A character vector of length one containing a single character or an empty string. Use "" to turn off the interpretation of comments altogether. |
| encoding |
encoding to be assumed for input strings. It is used to mark character strings as known to be in Latin-1 or UTF-8. It is not used to re-encode the input, but allows R to handle encoded strings in their native encoding (if one of those two). |
| text |
character string. If file is not supplied and this is, then data are read from the value of text via a text connection. Notice that a literal string can be used to include (small) data sets within R code. |
| skipNul |
logical: should nuls be skipped? |
Description
To import data from a CSV file, click on the File - CSV File item in the ribbon toolbar.
The dialog for data importing from CSV files is displayed. In this dialog you can set several parameters. The first parameter is File Name - the path to the file on the computer disk. You can define this path manually or using the Open button. If you use the button, the program will automatically format the correct path.
The R Environment specifics is that the slash mark (“/") is used as the directories separator, instead of the backslash (“\"). If you paste the file name manually, you must also manually change these separators. If you define it using the Open button, separators are set automatically in the correct form.
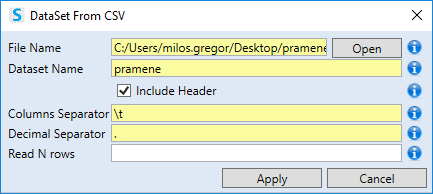
After entering the File Name, you define the Dataset Name - the name of the dataset within the Stagraph project. Next, you can setup several properties - Include Header (contains the file in the first row variable names), Columns Separator (character that separate columns), Decimal Separator (separating the decimal places in numbers - by default dot) and finally Read N Rows (the maximum number of rows readed from the file).
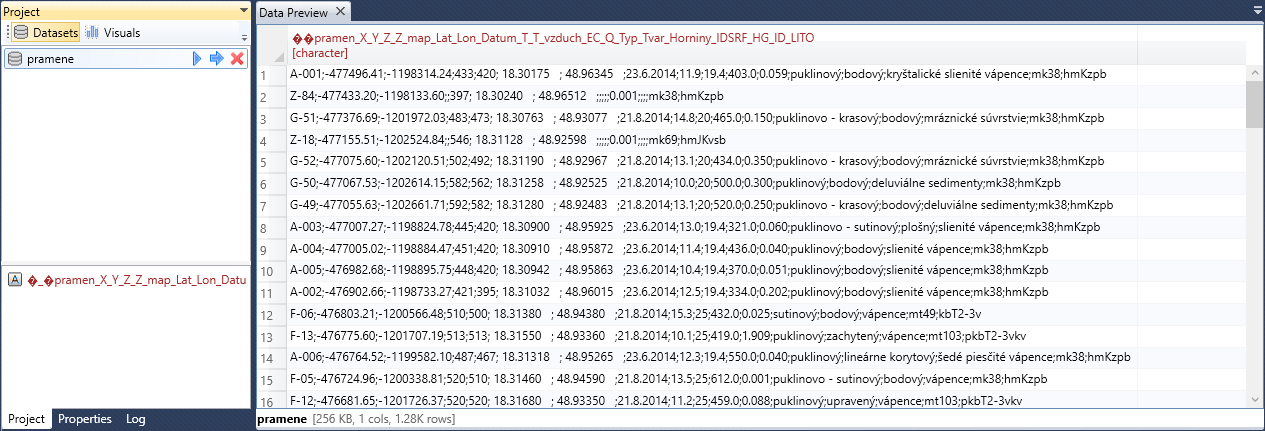
After setting all parameters and click on the Apply button, the defined dataset was imported into the program. The example is shown in the following image. From the Data Preview Document we see that all variables are displayed in one column. This is caused by the use of an incorrect columns separator - tab (in file is semicolon used).
You can change this setting even after importing, if you double-click on the imported dataset in the Project Panel. Its definition will appear in the Properties Panel. If you click on the first entry in the list (data_csv), you can adjust several properties of data import. In the following example, we changed the sep (column separator) to “;". Subsequently, the CSV file is imported and parsed correctly.
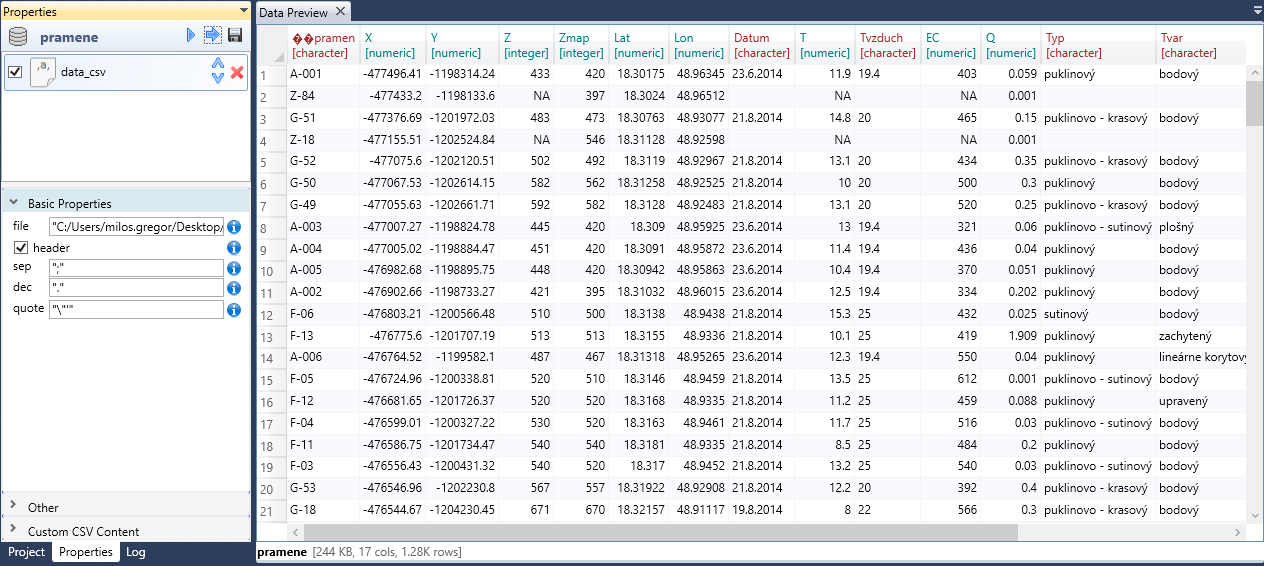
In the Properties Panel you can edit several import parameters. These are divided into three panels - Basic Properties, Other and Custom CSV Content. In theBasic Properties panel, you find basic and most used parameters.
The first parameter is file. Use this parameter to set / change the CSV file path. If you right-click the text-box a contextual menu with help features will appear. Using the Open… item you can select a file on the computer disk. The other two items - Sample URL and Sample FTP interts a sample functions for file import via the URL and FTP protocol. Then you just change the URL / FTP path to the file.
Another parameter is sep. This parameter defines columns separator. In the contextual menu you will find examples of the most commonly used separators. You can set any type of separator. Applied separator always close into quotes, because the value can be in Stagraph defined as an R function as well.
Parameter dec serves to define a decimal separator at numeric values in a file. Value is also enclosed in quotes. In the contextual menu, you find help functions for setting the property to Point or Comma.
Finally, you can set the quote parameter in the panel. Using the quote parameter, you can set whether text variables in CSV file are enclosed in the quotation marks. As in previous cases, in the contextual menu you will find examples of the most used settings.
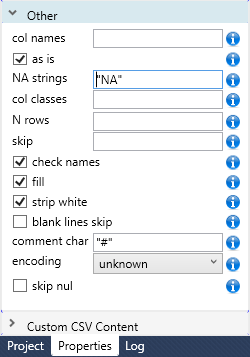
Additional data import properties can be found in the Other panel. These settings are used in special cases. If you can not set them, keep the default values.
The first parameter in this group is col names. Use this parameter to redefine column names from a CSV file. This function is useful if the CSV file does not contain variable names in the first row. You can also find an example of this parameter in the contextual menu. The names are defined using the c function. Individual names (enclosed in quotes) are inserting into brackets. The number of names must be the same as the number of columns in the CSV file. You can define the names manually, for example:
c(“Col1", “Col2", “Col3","Col4")
or by R functions:
paste(“Col", 1:4)
If the column names are not in the CSV file and you have not defined them through the col names property, they will be generated automatically in the form of X1, X2 to Xn.
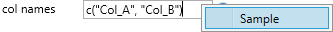
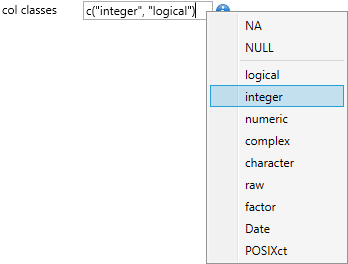
Using the next parameter - col classes, you can set the data format for each column. Just as in the previous case, you find the supported basic formats in the contextual menu. The format can be defined one for all variables (e.g. “character"), or individually for each column, for example:
c(“integer","string","string", “numeric", “numeric")
You can do this data formatting at import in this way, or you can do it later through Data Wrangling functions.
If your CSV file contains comments at the end of the line, you can use the comment char. The program subsequently ignores everything that follows the character.

Using other parameters, for example, you can define the encoding. A complete explanation of each parameter is in the Function Properties section.
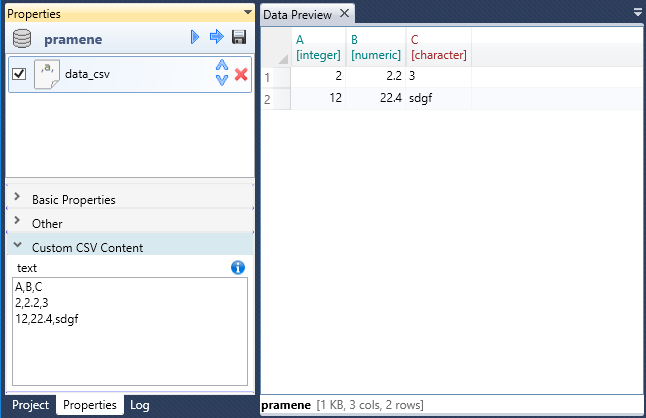
Finally, the Custom CSV Content panel remains. The data_csv function has one interesting property - text. If you leave the file property blank and you insert the custom csv content into the last text-box, it will automatically be used as input data and parsed. The advantage of this feature is that within the project file you have stored also input values. However, this feature is useful only for small datasets. The example is shown in the following illustration. You can apply other properties such as col names or skip to the content in this text-box.
CSV data is a widely used way of data sharing between applications and platforms. They are easy to read and process. That’s why Stagraph fully supports them. You can import CSV data with multiple properties and this import is fully customizable.